2.0 Model Training
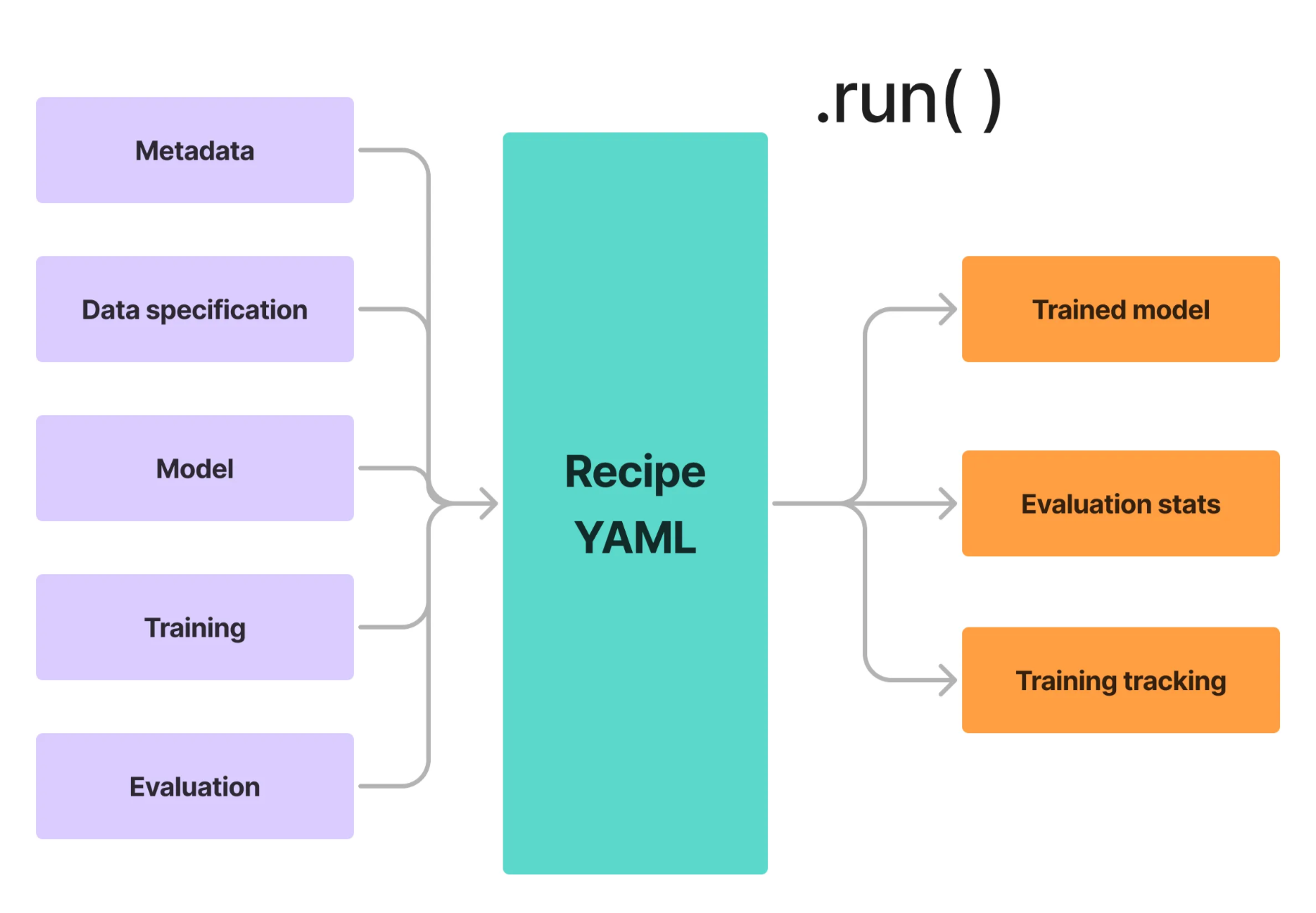
How the Anvil Infrastructure Works
Anvil is our primary infrastructure for model training and evaluation, built to support scalable, reproducible, and rigorous development of ADMET prediction models.
Recognizing that building the best models requires training many variants, ensuring their reproducibility, and enabling robust performance comparisons, Anvil centers around a YAML-based recipe system.
These recipes allow users to specify model architectures and training procedures in a standardized, shareable format—minimizing code duplication while supporting both deep learning and traditional machine learning approaches.
Designed with both internal and external engagement in mind, Anvil aims to lower the barrier for outside users to adopt and fine-tune models by offering simple, transparent workflows. Long-term, it will serve as a foundation for broader community involvement and model reuse.
Requirements
To run Anvil, you need:
A dataset that has been processed with
01_Curate_ChEMBL_Data.ipynb.A
YAMLfile with instructions for Anvil. We will show you how to create this file in this notebook.
Training a Model to Predict CYP3A4 Inhibition
Now that we have a cleaned a dataset, we can train a model to predict CYP3A4 inhibition.
This notebook will walk you through how to run the Anvil model training workflow with the CYP3A4 data processed and cleaned in previous notebooks.
Creating the YAML file
The heart of an anvil run is in its YAML configuration file. Here we specify nearly everything needed to:
load data
preprocess it
split the data appropriately into train/validation/test
featurize according to model selection
train the model
and, finally, validate on the test set (which generates performance metrics and plots)
We will walkthrough two YAML files: one for training a traditional machine learning model (anvil_lgbm.yaml) and one for training a deep learning model (anvil_chemprop.yaml).
Training a Traditional Machine Learning model: LightGBM
Here is a YAML file for training a LightGBM (LGBM) model. We are using the previously curated CYP3A4 data from ChEMBL. Be sure to read through the comments (in green) to understand each field.
At a minimum, ensure
resource,input_col, andtarget_colsare specified to match your dataset, as these will vary per datasetThe
proceduresection may not need much modification, especially if not tweaking parameters, but look it over to make sure it’s sensible
# This spection specifies the data that will be input into the model
data:
# Specify the dataset file
resource: ../../01_Data_Curation/processed_data/processed_CYP3A4_inhibition.csv
type: intake
input_col: OPENADMET_CANONICAL_SMILES
# Specify each (1+) of the target columns, or the column that you're trying to predict
target_cols:
- OPENADMET_LOGAC50
dropna: true
# Additional metadata
# This should be descriptive as the tags in these fields will annotate downstream Anvil processes:
# mainly, when you do model inference
metadata:
authors: Your Name
email: youremail@email.com
biotargets:
- CYP3A4
build_number: 0
description: basic regression using a LightGBM model
driver: sklearn
name: lgbm_pchembl
tag: openadmet-chembl
tags:
- openadmet
- test
- pchembl
version: v1
# Section specifying training procedure:
# What model will you use?
# What featurizers will the model use?
# What hyperparameters will the mdoel use?
procedure:
# Featurization specification
feat:
# Using concatenated features, which combines multiple featurizers
# here we use DescriptorFeaturizer and FingerprintFeaturizer for 2D RDKit descriptors and ECFP4 fingerprints
# See openadmet.models.features
type: FeatureConcatenator
# Add parameters for the featurizer. Full description of the featurizer options are in Section 5.
params:
featurizers:
DescriptorFeaturizer:
descr_type: "desc2d"
FingerprintFeaturizer:
fp_type: "ecfp:4"
# Model specification
model:
# Indicate model type
# See openadmet.models.architecture for all model types
type: LGBMRegressorModel
# Specify model parameters
params:
alpha: 0.005
learning_rate: 0.05
n_estimators: 500
# Specify data splits
split:
# Specify how data will be split
# See openadmet.models.split
type: ShuffleSplitter
# Specify split parameters
params:
random_state: 42
train_size: 0.8
val_size: 0.0 # For LGBM, no validation set is needed
test_size: 0.2 # If you want to compare tree-based models with Dl models later, the test sizes should match
# Specify training configuration
train:
# Specify the trainer, here SKLearnBasicTrainer as model has an sklearn interface
# could also use SKLearnGridSearchTrainer for hyperparameter tuning
type: SKLearnBasicTrainer
# Section specifying report generation
# What cross validation splits will you use?
# You can also specify the min and max values of your plots
report:
# Configure evaluation
eval:
# Generate regression metrics
- type: RegressionMetrics
params: {}
# Generate regression plots & do cross validation
- type: SKLearnRepeatedKFoldCrossValidation
params:
axes_labels:
- True pAC50
- Predicted pAC50
max_val: 10
min_val: 3
pXC50: true
n_splits: 5
n_repeats: 5
title: True vs Predicted pAC50 on test set
After you have created or modified this YAML file to your liking, you can run the workflow with the below command either in a bash cell or in your command line:
openadmet anvil --recipe-path <your_file.yaml> --output-dir <output folder name>
This may take 5-10 minutes to run, depending on the number of epochs, your hyperparameters (e.g. learning rate), etc.
[1]:
%%bash
export OADMET_NO_RICH_LOGGING=1
openadmet anvil --recipe-path anvil_lgbm.yaml --output-dir lgbm
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/hyperopt/atpe.py:19: UserWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html. The pkg_resources package is slated for removal as early as 2025-11-30. Refrain from using this package or pin to Setuptools<81.
import pkg_resources
2025-10-21 11:41:13.422 | INFO | openadmet.models.anvil.specification:to_workflow:725 - Making workflow from specification
Workflow initialized successfully with recipe: anvil_lgbm.yaml
2025-10-21 11:41:13.587 | INFO | openadmet.models.anvil.workflow:run:232 - Running workflow from directory lgbm
2025-10-21 11:41:13.587 | INFO | openadmet.models.anvil.workflow:run:235 - Running with driver sklearn
2025-10-21 11:41:13.587 | INFO | openadmet.models.anvil.workflow:run:238 - Loading data
2025-10-21 11:41:13.595 | INFO | openadmet.models.anvil.specification:_read_single_resource:264 - 4800 total rows. 0 NaN rows were dropped.
2025-10-21 11:41:13.595 | INFO | openadmet.models.anvil.workflow:run:247 - Splitting data from single resource
2025-10-21 11:41:13.597 | INFO | openadmet.models.anvil.workflow:run:249 - Data loaded
2025-10-21 11:41:13.605 | INFO | openadmet.models.anvil.workflow:run:264 - Data split
2025-10-21 11:41:13.605 | INFO | openadmet.models.anvil.workflow:run:267 - Featurizing data
2025-10-21 11:41:39.923 | INFO | openadmet.models.anvil.workflow:run:306 - No transform specified, skipping
2025-10-21 11:41:39.923 | INFO | openadmet.models.anvil.workflow:run:308 - Data featurized
2025-10-21 11:41:39.923 | INFO | openadmet.models.anvil.workflow:_train:100 - Building model
2025-10-21 11:41:39.923 | INFO | openadmet.models.anvil.workflow:_train:102 - Model built
2025-10-21 11:41:39.923 | INFO | openadmet.models.anvil.workflow:_train:105 - Setting model in trainer
2025-10-21 11:41:39.924 | INFO | openadmet.models.anvil.workflow:_train:107 - Model set in trainer
2025-10-21 11:41:39.924 | INFO | openadmet.models.anvil.workflow:_train:110 - Training model
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:1408: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
2025-10-21 11:41:43.034 | INFO | openadmet.models.anvil.workflow:_train:112 - Model trained
2025-10-21 11:41:43.034 | INFO | openadmet.models.anvil.workflow:run:345 - Saving model
2025-10-21 11:41:43.045 | INFO | openadmet.models.anvil.workflow:run:350 - Model saved
2025-10-21 11:41:43.045 | INFO | openadmet.models.anvil.workflow:run:353 - Predicting
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMRegressor was fitted with feature names
warnings.warn(
2025-10-21 11:41:43.114 | INFO | openadmet.models.anvil.workflow:run:366 - Predictions made
2025-10-21 11:41:43.114 | INFO | openadmet.models.anvil.workflow:run:369 - Evaluating
2025-10-21 11:41:50.461 | INFO | openadmet.models.eval.cross_validation:evaluate:188 - Starting cross-validation
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:1408: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMRegressor was fitted with feature names
warnings.warn(
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:1408: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMRegressor was fitted with feature names
warnings.warn(
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:1408: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMRegressor was fitted with feature names
warnings.warn(
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:1408: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMRegressor was fitted with feature names
warnings.warn(
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:1408: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMRegressor was fitted with feature names
warnings.warn(
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:1408: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMRegressor was fitted with feature names
warnings.warn(
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:1408: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMRegressor was fitted with feature names
warnings.warn(
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:1408: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMRegressor was fitted with feature names
warnings.warn(
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:1408: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMRegressor was fitted with feature names
warnings.warn(
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:1408: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMRegressor was fitted with feature names
warnings.warn(
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:1408: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMRegressor was fitted with feature names
warnings.warn(
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:1408: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMRegressor was fitted with feature names
warnings.warn(
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:1408: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMRegressor was fitted with feature names
warnings.warn(
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:1408: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMRegressor was fitted with feature names
warnings.warn(
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:1408: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMRegressor was fitted with feature names
warnings.warn(
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:1408: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMRegressor was fitted with feature names
warnings.warn(
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:1408: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMRegressor was fitted with feature names
warnings.warn(
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:1408: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMRegressor was fitted with feature names
warnings.warn(
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:1408: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMRegressor was fitted with feature names
warnings.warn(
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:1408: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMRegressor was fitted with feature names
warnings.warn(
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:1408: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMRegressor was fitted with feature names
warnings.warn(
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:1408: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMRegressor was fitted with feature names
warnings.warn(
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:1408: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMRegressor was fitted with feature names
warnings.warn(
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:1408: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMRegressor was fitted with feature names
warnings.warn(
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:1408: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/Users/cynthiaxu/miniforge3/envs/demos/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMRegressor was fitted with feature names
warnings.warn(
2025-10-21 11:43:12.490 | INFO | openadmet.models.eval.cross_validation:evaluate:214 - Cross-validation complete
2025-10-21 11:43:15.527 | INFO | openadmet.models.anvil.workflow:run:388 - Evaluation done
Workflow completed successfully
The outputs of the Anvil workflow are in /anvil_training:
/datafolder includes the split data, saved as.csv/recipe_componentsfolder contains the inputs from the2.1_anvil_lgbm.yamlfile split by sectioncross_validation_metrics.jsonis the cross validation metrics of the model saved as a.jsonfilemodel.jsonis the model’s hyperparameters saved as a.jsonfileregression_metrics.jsonis the regression metrics saved as a.jsonfilemodel.pklis the trained model saved as.pklwhich can be loaded and used for predictions elsewherecross_validation_regplot.pngis a plot of the cross validation metrics of the modelanvil_recipe.yamlis a copy of the input.yaml
Here are the results of above trained LGBM model:
Training a Deep Learning model: ChemProp
Our framework is also capable of training deep learning models, but for ease of demonstration on CPU, we won’t actually train the model here. We recommend training deep learning models on GPU.
As an example, we’ve provided an already trained ChemProp model for you to look at for this demo.
Here is a YAML file (anvil_chemprop.yaml) for training OpenADMET’s ChemProp model. We are using the same ChEMBL CYP3A4 dataset. Be sure to note the different fields required for deep learning.
# This spection specifies the input data
data:
# Specify the dataset file
resource: ../01_Data_Curation/processed_data/processed_CYP3A4_inhibition.csv
type: intake
input_col: OPENADMET_CANONICAL_SMILES
# Specify each (1+) of the target columns, or the column that you're trying to predict
target_cols:
- OPENADMET_LOGAC50
# Additional metadata
metadata:
authors: Your Name
email: youremail@mail.com
biotargets:
- CYP3A4
build_number: 0
description: basic regression using a ChemProp multitask task model
driver: pytorch
name: chemprop_pchembl
tag: chemprop-CYP3A4-chembl
tags:
- openadmet
- test
version: v1
# Section specifying training procedure
procedure:
# Featurization specification
feat:
# Using the ChemPropFeaturizer (for ChemProp model)
# See openadmet.models.features
type: ChemPropFeaturizer
# No parameters passed
params: {}
# Model specification
model:
# Indicate model type
# See openadmet.models.architecture
type: ChemPropModel
# Specify model parameters
params:
depth: 4
ffn_hidden_dim: 1024
ffn_hidden_num_layers: 4
message_hidden_dim: 2048
dropout: 0.2
batch_norm: True
messages: bond
n_tasks: 1 # Number of tasks should match the number of target columns
from_chemeleon: False
# Specify data splits
split:
# Specify how data will be split
# See openadmet.models.split
type: ShuffleSplitter
# Specify split parameters
params:
random_state: 42
train_size: 0.7
val_size: 0.1
test_size: 0.2
# Specify training configuration
train:
# Specify the trainer, here LightningTrainer as ChemProp is a PyTorch Lightning model
# See openadmet.models.trainer
type: LightningTrainer
# Specify model parameters
params:
accelerator: gpu
early_stopping: true
early_stopping_patience: 10
early_stopping_mode: min
early_stopping_min_delta: 0.001
max_epochs: 50
monitor_metric: val_loss
use_wandb: false
wandb_project: demos # Specify wandb project name according to guidelines
# Section specifying report generation
report:
# Configure evaluation
eval:
# Generate regression metrics
- type: RegressionMetrics
params: {}
# Generate regression plots & do cross validation
- type: PytorchLightningRepeatedKFoldCrossValidation
params:
axes_labels:
- True LogAC50
- Predicted LogAC50
n_repeats: 5
n_splits: 5
random_state: 42
pXC50: true
title: True vs Predicted LogAC50 on test set
The command is
openadmet anvil --recipe-path anvil_chemprop.yaml --output-dir chemprop
We recommend training deep learning models on GPU.
The results of a pre-trained version we provide are shown here
Training a Multitask Deep Learning Model: ChemProp
Similarly to the single task deep learning example above, we’ve gone ahead and trained this model for you. We recommend training deep learning models on GPU.
There may be instances where you will want to train a model to predict compound activity on multiple protein targets.
For example, you may have endpoints that share a biochemical pathway such that activity on one is thought to be somewhat correlated to the other.
It would thus be useful to train a multitask model on multiple targets. The YAML file example shown below is anvil_multitask.yaml.
# Section specifying input data
data:
# Specify the dataset file, can be S3 path etc.
resource: ../01_Data_Curation/processed_data/multitask.parquet
# must be intake
type: intake
# Specify input column containing SMILES
input_col: OPENADMET_CANONICAL_SMILES
# Specify whether or not to drop NaN data rows
dropna: False
# Specify each (1+) of the target columns
target_cols:
- OPENADMET_LOGAC50_cyp2j2
- OPENADMET_LOGAC50_cyp3a4
- OPENADMET_LOGAC50_cyp1a2
- OPENADMET_LOGAC50_pxr
- OPENADMET_LOGAC50_cyp2d6
- OPENADMET_LOGAC50_cyp2c9
- OPENADMET_LOGAC50_ahr
# Additional metadata
metadata:
authors: Your Name
email: youremail@mail.com
biotargets:
- CYP3A4
- CYP2J2
- CYP1A2
- CYP2D6
- CYP2C9
- PXR
- AHR
build_number: 0
description: basic regression using a ChemProp multitask task model
driver: pytorch
name: chemprop_pchembl
tag: chemprop
tags:
- openadmet
- test
- chemprop
version: v1
# Section specifying training procedure
procedure:
# Featurization specification
feat:
# Using the ChemPropFeaturizer (for ChemProp model)
# See openadmet.models.features
type: ChemPropFeaturizer
# No parameters passed
params: {}
# Model specification
model:
# Indicate model type
# See openadmet.models.architecture
type: ChemPropModel
# Specify model parameters
params:
depth: 4
ffn_hidden_dim: 1024
ffn_hidden_num_layers: 4
message_hidden_dim: 2048
dropout: 0.2
batch_norm: True
messages: bond
n_tasks: 7 # Number of tasks should match the number of target columns
from_chemeleon: False
# Specify data splits
split:
# Specify how data will be split, can be ShuffleSplitter, ScaffoldSplitter, etc.
# See openadmet.models.split
type: ShuffleSplitter
# Specify split parameters
params:
random_state: 42
train_size: 0.7
val_size: 0.1
test_size: 0.2
# Specify training configuration
train:
# Specify the trainer, here LightningTrainer as ChemProp is a PyTorch Lightning model
# See openadmet.models.trainer
type: LightningTrainer
# Specify model parameters
params:
accelerator: gpu
early_stopping: true
early_stopping_patience: 10
early_stopping_mode: min
early_stopping_min_delta: 0.001
max_epochs: 50
monitor_metric: val_loss
use_wandb: false
wandb_project: demos # Specify wandb project name according to guidelines
# Section specifying report generation
report:
# Configure evaluation
eval:
# Generate regression metrics
- type: RegressionMetrics
params: {}
# Generate regression plots & do cross validation
- type: PytorchLightningRepeatedKFoldCrossValidation
params:
axes_labels:
- True LogAC50
- Predicted LogAC50
n_repeats: 5
n_splits: 5
random_state: 42
pXC50: true
title: Multitask True vs Predicted LogAC50 on test set
The results of a pre-trained version we provide are shown here
We will examine the full results of these models in 03_Model_Comparison.
Congrats! You now know how to train models with the Anvil workflow. Explore our model catalog for other model architectures and featurizers.
- Now let’s compare the performance of our models!
End of
02_Training_Models~